一起内核 hard LOCKUP 问题分析
前段时间碰到一起服务器宕机故障,
机器重启后在 /var/crash 找到了崭新的 crash dump 文件夹,
看来是一起新鲜出炉的 kernel crash 故障。
在 crash 目录下的 vmcore-dmesg.txt 文件中发现一系列如下形式的 kernel hard LOCKUP[1] 日志:
[xxxxxx.xxxxxx] NMI watchdog: Watchdog detected hard LOCKUP on cpu x
[xxxxxx.xxxxxx] NMI watchdog: Watchdog detected hard LOCKUP on cpu y
[xxxxxx.xxxxxx] NMI watchdog: Watchdog detected hard LOCKUP on cpu z
这是一台核数不少的物理机,
日志显示几乎有一半的 CPU 发生了 hard LOCKUP.
开动 crash[2] 分析,
kernel crash 的堆栈现场如下:
crash> bt
PID: 0 TASK: ffff8820d3ad8fd0 CPU: x COMMAND: "swapper/x"
#0 [ffff883ffde859f0] machine_kexec at ffffffff8105c4cb
#1 [ffff883ffde85a50] __crash_kexec at ffffffff81104a32
#2 [ffff883ffde85b20] panic at ffffffff8169dc5f
#3 [ffff883ffde85ba0] nmi_panic at ffffffff8108771f
#4 [ffff883ffde85bb0] watchdog_overflow_callback at ffffffff8112fa75
#5 [ffff883ffde85bc8] __perf_event_overflow at ffffffff8116e561
#6 [ffff883ffde85c00] perf_event_overflow at ffffffff811770b4
#7 [ffff883ffde85c10] intel_pmu_handle_irq at ffffffff81009f78
#8 [ffff883ffde85e38] perf_event_nmi_handler at ffffffff816ac06b
#9 [ffff883ffde85e58] nmi_handle at ffffffff816ad427
#10 [ffff883ffde85eb0] do_nmi at ffffffff816ad65d
#11 [ffff883ffde85ef0] end_repeat_nmi at ffffffff816ac8d3
[exception RIP: tick_nohz_stop_sched_tick+755]
RIP: ffffffff810f3483 RSP: ffff8820d3aebe50 RFLAGS: 00000002
RAX: 0000000035696841 RBX: 0002b313f9231dc0 RCX: 000000000000001f
RDX: 0000000000000005 RSI: 0002b313e403c95f RDI: ffff883ffde8fe80
RBP: ffff8820d3aebe98 R8: ffff8820d3ae8000 R9: 000000012d45c83d
R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000005
R13: 000000012d45c9a0 R14: ffff883ffde8fe80 R15: ffff8820d3ae8000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
--- <NMI exception stack> ---
#12 [ffff8820d3aebe50] tick_nohz_stop_sched_tick at ffffffff810f3483
#13 [ffff8820d3aebe60] sched_clock at ffffffff81033619
#14 [ffff8820d3aebea0] __tick_nohz_idle_enter at ffffffff810f359f
#15 [ffff8820d3aebed0] tick_nohz_idle_enter at ffffffff810f3adf
#16 [ffff8820d3aebee0] cpu_startup_entry at ffffffff810e7b1a
#17 [ffff8820d3aebf28] start_secondary at ffffffff81051af6
根据堆栈现场可以观察到一下几点:
- kernel panic 时运行的是 swapper 进程(也就是 idle 空闲进程,跟内存 swap 没关系);
tick_nohz_stop_sched_tick() 函数说明 idle 进程正在准备进入 tickless[3][4] 状态;- 此时来了一个 NMI 不可屏蔽中断[5],
NMI 中断处理函数判断当前 CPU 发生了 hard LOCKUP,然后触发了 kernel crash;
hard LOCKUP 意味着系统在屏蔽 IRQ 中断的场景下长时间运行于内核态,时间超过 watchdog_thresh 配置,
watchdog_thresh 默认配置是 10s。
系统在内核态中绕不出来,而且有大量的 CPU 都发生了 hard LOCKUP,
猜测是内核某个代码死循环了。
从上面的堆栈现场中可以看到,NMI 中断发生前系统运行的是这行代码:
#12 [ffff8820d3aebe50] tick_nohz_stop_sched_tick at ffffffff810f3483
把 tick_nohz_stop_sched_tick() 函数的反汇编代码展开来看:
crash> dis tick_nohz_stop_sched_tick
0xffffffff810f3190 <tick_nohz_stop_sched_tick>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff810f3195 <tick_nohz_stop_sched_tick+5>: push %rbp
0xffffffff810f3196 <tick_nohz_stop_sched_tick+6>: mov %rsp,%rbp
0xffffffff810f3199 <tick_nohz_stop_sched_tick+9>: push %r15
0xffffffff810f319b <tick_nohz_stop_sched_tick+11>: push %r14
...
0xffffffff810f31ce <tick_nohz_stop_sched_tick+62>: mov (%rax),%rax
0xffffffff810f31d1 <tick_nohz_stop_sched_tick+65>: mov %rax,-0x40(%rbp)
0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>: mov 0x8f7fe5(%rip),%eax # 0xffffffff819eb1c0 <jiffies_lock>
0xffffffff810f31db <tick_nohz_stop_sched_tick+75>: test $0x1,%al
0xffffffff810f31dd <tick_nohz_stop_sched_tick+77>: jne 0xffffffff810f3481 <tick_nohz_stop_sched_tick+753>
0xffffffff810f31e3 <tick_nohz_stop_sched_tick+83>: mov 0xda299e(%rip),%rbx # 0xffffffff81e95b88 <last_jiffies_update>
0xffffffff810f31ea <tick_nohz_stop_sched_tick+90>: mov 0xa37e0f(%rip),%r13 # 0xffffffff81b2b000 <.vvar>
0xffffffff810f31f1 <tick_nohz_stop_sched_tick+97>: cmp 0x8f7fc9(%rip),%eax # 0xffffffff819eb1c0 <jiffies_lock>
0xffffffff810f31f7 <tick_nohz_stop_sched_tick+103>: jne 0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>
0xffffffff810f31f9 <tick_nohz_stop_sched_tick+105>: lea -0x38(%rbp),%rsi
0xffffffff810f31fd <tick_nohz_stop_sched_tick+109>: mov %r13,0xd8(%r14)
0xffffffff810f3204 <tick_nohz_stop_sched_tick+116>: mov %r12d,%edi
...
0xffffffff810f3477 <tick_nohz_stop_sched_tick+743>: jmpq 0xffffffff810f32b0 <tick_nohz_stop_sched_tick+288>
0xffffffff810f347c <tick_nohz_stop_sched_tick+748>: callq 0xffffffff81087720 <__stack_chk_fail>
0xffffffff810f3481 <tick_nohz_stop_sched_tick+753>: pause
0xffffffff810f3483 <tick_nohz_stop_sched_tick+755>: jmpq 0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>
0xffffffff810f3488 <tick_nohz_stop_sched_tick+760>: cmpl $0x2,0x68(%r14)
0xffffffff810f348d <tick_nohz_stop_sched_tick+765>: nopl (%rax)
0xffffffff810f3490 <tick_nohz_stop_sched_tick+768>: jne 0xffffffff810f3321 <tick_nohz_stop_sched_tick+401>
0xffffffff810f3496 <tick_nohz_stop_sched_tick+774>: mov %r14,%rdi
0xffffffff810f3499 <tick_nohz_stop_sched_tick+777>: callq 0xffffffff810b4d90 <hrtimer_cancel>
0xffffffff810f349e <tick_nohz_stop_sched_tick+782>: jmpq 0xffffffff810f3321 <tick_nohz_stop_sched_tick+401>
...
可以看到 0xffffffff810f3483 处的代码是一条跳转到 0xffffffff810f31d5 处的指令,
0xffffffff810f31d5 之前的指令则都是一些函数堆栈初始化相关的指令,
这说明 0xffffffff810f31d5 处的指令对应的应该是函数最开始的几行代码。
查看 tick_nohz_stop_sched_tick() 函数的源码:
crash> dis -s tick_nohz_stop_sched_tick
FILE: kernel/time/tick-sched.c
LINE: 578
573 ts->next_tick.tv64 = 0;
574 }
575
576 static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
577 ktime_t now, int cpu)
* 578 {
579 struct clock_event_device *dev = __get_cpu_var(tick_cpu_device).evtdev;
580 u64 basemono, next_tick, next_tmr, next_rcu, delta, expires;
581 unsigned long seq, basejiff;
582 ktime_t tick;
583
584 /* Read jiffies and the time when jiffies were updated last */
585 do {
586 seq = read_seqbegin(&jiffies_lock);
587 basemono = last_jiffies_update.tv64;
588 basejiff = jiffies;
589 } while (read_seqretry(&jiffies_lock, seq));
590 ts->last_jiffies = basejiff;
591
592 if (rcu_needs_cpu(cpu, &next_rcu) ||
593 arch_needs_cpu(cpu) || irq_work_needs_cpu()) {
594 next_tick = basemono + TICK_NSEC;
595 } else {
...
可以看到 tick_nohz_stop_sched_tick() 函数最前几行代码执行的是读取 jiffies_lock[6] 的操作,
jiffies_lock 是内核中用到的轻量级读写锁 seqlock_t [7],
这里主要用来保护内核时钟滴答变量 jiffies。
对比 0xffffffff810f31d5 处的指令:
0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>: mov 0x8f7fe5(%rip),%eax # 0xffffffff819eb1c0 <jiffies_lock>
再来看 jiffies_lock 的地址:
crash> p &jiffies_lock
$2 = (seqlock_t *) 0xffffffff819eb1c0 <jiffies_lock>
0xffffffff810f31d5 处指令执行时,
rip 指向的是下一条指令的地址,也就是 0xffffffff810f31db,
所以有:
&jiffies_lock = rip(0xffffffff819eb1c0) + 0x8f7fe5 = 0xffffffff819eb1c0
和该处汇编代码上的注释是一致的,
说明 0xffffffff810f31d5 处代码执行的是读取 jiffies_lock 变量的操作,
对应的源码应该就是 586 行处的代码:
586 seq = read_seqbegin(&jiffies_lock);
目前为止还看不出哪处代码有产生死循环的可能,
目前有一个疑问是,
0xffffffff810f3483 这个地址几乎已经是函数末尾了,
代码为什么执行到这一处,
为什么会跳往接近函数开头 0xffffffff810f31d5 处的这个地址?
0xffffffff810f31d5 这个地址我们已经分析过,
它对应的是 seq = read_seqbegin(&jiffies_lock); 这行代码,
继续分析 0xffffffff810f31d5 下面的几行汇编代码:
0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>: mov 0x8f7fe5(%rip),%eax # 0xffffffff819eb1c0 <jiffies_lock>
0xffffffff810f31db <tick_nohz_stop_sched_tick+75>: test $0x1,%al
0xffffffff810f31dd <tick_nohz_stop_sched_tick+77>: jne 0xffffffff810f3481 <tick_nohz_stop_sched_tick+753>
可以看到 0xffffffff810f31dd 处代码往 0xffffffff810f3481 做了条件跳转,
而 0xffffffff810f3481 处的下一条指令的地址就是 0xffffffff810f3483:
0xffffffff810f3481 <tick_nohz_stop_sched_tick+753>: pause
0xffffffff810f3483 <tick_nohz_stop_sched_tick+755>: jmpq 0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>
这里似乎——构成了一个循环诶!
再来逐条分析函数最前面 0xffffffff810f31d5-0xffffffff810f31dd 的三条指令,
首先 0xffffffff810f31d5 处代码把 jiffies_lock 结构体中的某个字段读取到 eax 寄存器中:
0xffffffff810f31d5 <tick_nohz_stop_sched_tick+69>: mov 0x8f7fe5(%rip),%eax # 0xffffffff819eb1c0 <jiffies_lock>
我们来看 jiffies_lock 这个结构:
crash> p jiffies_lock
jiffies_lock = $5 = {
seqcount = {
sequence = 896100417
},
lock = {
{
rlock = {
raw_lock = {
val = {
counter = 0
}
}
}
}
}
}
很明显,0xffffffff810f31d5 处代码等价于 eax = jiffies_lock.seqcount.sequence。
再来看紧接着的 0xffffffff810f31db 处的指令:
0xffffffff810f31db <tick_nohz_stop_sched_tick+75>: test $0x1,%al
0xffffffff810f31db 处指令将 al 寄存器和 0x01 进行位与运算,
test 指令结果影响到 Flag 寄存器的 ZF 标志位,
ZF 标志为又会进一步影响下一条 0xffffffff810f31dd 处的 jne 指令的:
0xffffffff810f31dd <tick_nohz_stop_sched_tick+77>: jne 0xffffffff810f3481 <tick_nohz_stop_sched_tick+753>
如果 al & 0x01 不为零那么 ZF 标志位被置一,
jne 0xffffffff810f3481 条件成立跳转到 0xffffffff810f3481 执行 pause 暂停指令,
紧接着 0xffffffff810f3483 处的 jmp 指令又跳转到 0xffffffff810f31d5,
构成一个循环了有木有?
内核是不是卡在这个循环上了?
不难找出,这里代码构成死循环的条件是 jiffies_lock.seqcount.sequence 变量一直为奇数,
这样的话 test $0x1,%al 会一直将 ZF 标志为置一。
上面我们已经看到 jiffies_lock.seqcount.sequence 的值为奇数 896100417,
符合我们的猜想。
那么 jiffies_lock.seqcount.sequence 有没有可能一直保持奇数呢?
我们已经分析出内核当前执行的代码构成一个循环,
当前代码对应的是 seq = read_seqbegin(&jiffies_lock); 这行代码,
这行代码的作用是获取 jiffies_lock 读者锁,
查看 read_seqbegin() 的实现:
72 static inline unsigned __read_seqcount_begin(const seqcount_t *s)
73 {
74 unsigned ret;
75
76 repeat:
77 ret = READ_ONCE(s->sequence);
78 if (unlikely(ret & 1)) {
79 cpu_relax();
80 goto repeat;
81 }
82 return ret;
83 }
...
238 /*
239 * Read side functions for starting and finalizing a read side section.
240 */
241 static inline unsigned read_seqbegin(const seqlock_t *sl)
242 {
243 return read_seqcount_begin(&sl->seqcount);
244 }
...
不难看出,上面分析的那个循环对应的应该就是 __read_seqcount_begin() 函数中的这个 repeat 循环。
为什么 s->sequence 为奇数时 __read_seqcount_begin() 就让代码在 repeat 循环跳不出来呢?
这涉及到 seqlock_t 锁的实现。
s->sequence 初始化为偶数,
当写者获取锁是 s->sequence 先加一,
写者离开时再加一,
这样如果 s->sequence 为奇数便说明当前有写者在操作,
读者便进入 repeat 那段死循环中忙等待。
所以,当前那个 CPU 执行的代码持有 jiffies_lock 写者锁让当前这个 CPU 的内核代码进入死循环呢?
要确定这个问题只要把各个 CPU 当前的执行堆栈打出来大概就清楚了。
一查下去,
能把人吓一大跳,
这台机器上不管 CPU 上有没有检测出 hard LOCKUP,他们全部都处在这个死循环上!
也就是说,所有的 CPU 不是已经产生 hard LOCKUP 就是在进入 hard LOCKUP 的路上!
为什么会这样?
一个猜测内核代码在操作 jiffies_lock writer lock 上有 bug(读者不会修改 sequence 变量),
检查内核中对 jiffies_lock 的所有操作:
C symbol: jiffies_lock
File Function Line
0 jiffies.c <global> 70 __cacheline_aligned_in_smp DEFINE_SEQLOCK(jiffies_lock);
1 tick-internal.h <global> 9 extern seqlock_t jiffies_lock;
2 jiffies.c get_jiffies_64 79 seq = read_seqbegin(&jiffies_lock);
3 jiffies.c get_jiffies_64 81 } while (read_seqretry(&jiffies_lock, seq));
4 tick-common.c tick_periodic 66 write_seqlock(&jiffies_lock);
5 tick-common.c tick_periodic 72 write_sequnlock(&jiffies_lock);
6 tick-common.c tick_setup_periodic 144 seq = read_seqbegin(&jiffies_lock);
7 tick-common.c tick_setup_periodic 146 } while (read_seqretry(&jiffies_lock, seq));
8 tick-sched.c tick_do_update_jiffies64 65 write_seqlock(&jiffies_lock);
9 tick-sched.c tick_do_update_jiffies64 88 write_sequnlock(&jiffies_lock);
a tick-sched.c tick_do_update_jiffies64 91 write_sequnlock(&jiffies_lock);
b tick-sched.c tick_init_jiffy_update 102 write_seqlock(&jiffies_lock);
c tick-sched.c tick_init_jiffy_update 107 write_sequnlock(&jiffies_lock);
d tick-sched.c tick_nohz_stop_sched_tick 586 seq = read_seqbegin(&jiffies_lock);
e tick-sched.c tick_nohz_stop_sched_tick 589 } while (read_seqretry(&jiffies_lock, seq));
f timekeeping.c xtime_update 2179 write_seqlock(&jiffies_lock);
g timekeeping.c xtime_update 2181 write_sequnlock(&jiffies_lock);
以上一系列 jiffies_lock 引用中的 writer 操作中,
代码逻辑或者内存屏障的使用上都看不出有明显的问题。
问题一时没法继续分析下去了,
搁置了很长时间,
直到有一天,
心血来潮在 google 上用关键字 “intel cpu unexpected register value” 搜了一把,
google 的第一条记录是 Intel 6 代处理器的固件升级文档:
第二页则看到一篇非常有价值的文章
Intel’s Skylake and Kaby Lake CPUs have nasty hyper-threading bug:
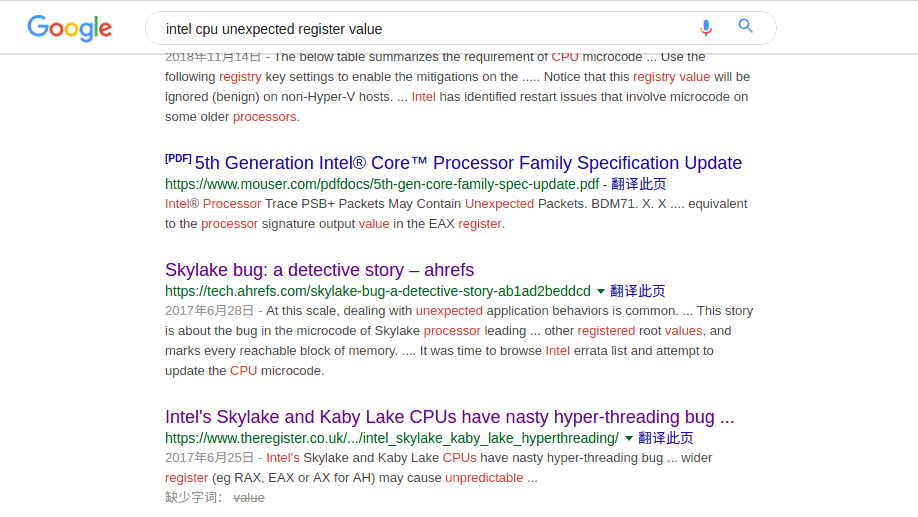
这是去年六月份出来的一篇文章,
这篇文章提到 Intel Skylake 和 Kaby Lake 系列 CPU 的超线程技术存在严重的问题,
而 google 搜索出来的第一条记录的固件升级文档则包含了该问题的记录。
文章中提到:
Under complex micro-architectural conditions, short loops of less than 64 instructions that use AH, BH, CH or DH registers as well as their corresponding wider register (eg RAX, EAX or AX for AH) may cause unpredictable system behaviour. This can only happen when both logical processors on the same physical processor are active.
Symptoms can include “application and system misbehaviour, data corruption, and data loss”.
就是说 Intel 该系列的 CPU 在启用超线程的场景下
使用 AH,EAX,RAX 等寄存器的短循环可能会产生不可预知的系统行为,
包括数据错误和数据丢失。
这个场景和我们遇到的问题非常相似,
一个猜想就是:
sequence 的值因为 Intel CPU 的这个 bug 而产生奇偶性翻转,
最终导致整个 kernel crash。
不过,值得注意的一点是,我们故障内核的代码中使用的是 AL 寄存器,
而且我们的 CPU 型号和上述文章中描述的故障 CPU 型号也不一致。
一个比较阴谋论的猜测就是:我们的使用的 CPU 也存在类似 bug,
但是 Intel 故意不公布相关型号 CPU 的故障信息
(考虑到 Intel 在他们固件升级文档中关于故障的描述是如此的语焉不详,
这个怀疑不能说毫无根据),
毕竟如果他们众多型号的服务器 CPU 都存在以上问题,
那是很影响产品销售和公司信誉的,
暗搓搓发布一版固件升级偷偷摸摸把问题修复掉,
对于 Intel 来说可能是最好的解决办法。
References
[1] Softlockup detector and hardlockup detector (aka nmi_watchdog)
[2] KERNEL CRASH DUMP GUIDE
[3] TICKLESS KERNEL
[4] NO_HZ: Reducing Scheduling-Clock Ticks
[5] Non-maskable interrupt
[6] Reinventing the timer wheel
[7] Driver porting: mutual exclusion with seqlocks