Raft 笔记(一)—— 选主
1. Raft 概要和选主
Raft 是一个分布式共识算法,
分布式意味着多节点参与,共识指多个节点对某个值达成共识,
这个定义留到后面我们会再详细解释。
Raft 算法由几个模块组成,分别是:
- 选主
- 日志复制
- 安全性保障
这边文章主要围绕的点是 Raft 中的选主流程。
Raft 算法中的节点有三种角色,分别是:
- Follower —— 从节点
- Candidate —— 候选节点
- Leader —— 主节点
Raft 算法中所有来自客户端的请求都是通过主节点来完成的,
如果请求发送到非主节点,它会被进一步转发到主节点进行处理。
Raft 中的选主暨在一个任期(term)内从一个或多个候选节点选出主节点。
这里有一个任期的概念,初始任期为零,一次新的选举意味着一个新的任期,
它在上个任期的基础上加一。
Raft 中的节点之间通过 RPC 通信,有两个核心的 RPC 分别是:
- AppendEntries
- RequestVote
当前我们可以把 AppendEntries 理解为 Raft 中主节点向其他节点发送心跳包的 RPC,
它通过这个心条包来维持主节点的角色。
当从节点超过一定时限未收到心跳包时便会转变为候选节点,
并开始一次心的选举。
在一次选举中候选节点向所有其他节点发送 RequsstVote RPC 请求投票,
当它获得超过半数节点的投票后便可成为新的主节点。
候选节点总是投票给自己,从节点在一个任期内总是把票投给它第一个收到 RequsstVote RPC 的候选节点。
如果一次投票中出现了平局的结果,那么候选节点会继续开始一场新的选举。
这两个 RPC 的返回值都包含节点当前的任期,
一旦请某个节点发现 RPC 返回的任期比自己当前的任期高它会理解跟新自己当前的任期,
并转为从节点。
来看 Raft 算法中各个角色之间的状态转化关系图:
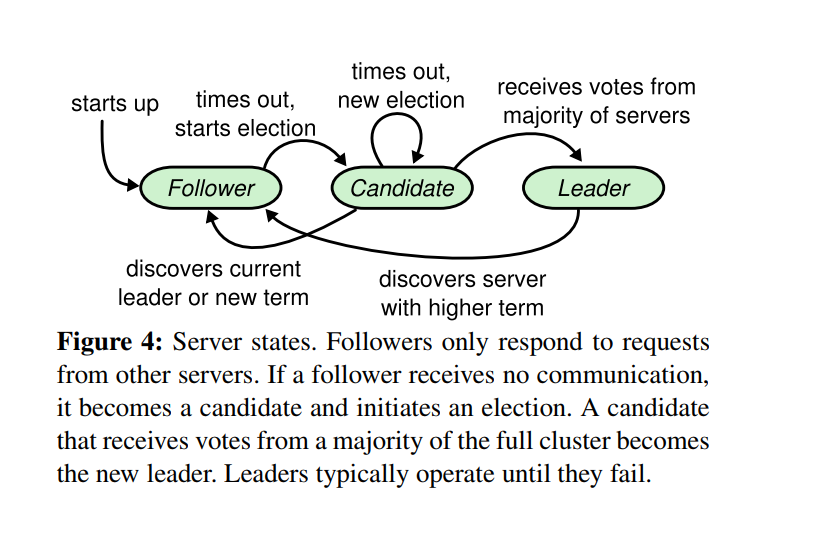
各种状态之间的转换条件如下:
| 旧状态\新状态 |
Follower |
Candidate |
Leader |
| Follower |
- |
election timeout,未收到 Leader 心跳包可能的原因:1. 主节点挂了 2. 网络中断、延迟 |
- |
| Candidate |
1. 发现合法的主节点(当前任期、或者更高任期)2. RPC response 发现更高的任期 |
1. 选举超时 2. 选举平局 |
获得超过半数的投票 |
| Leader |
RPC response 发现更高的任期:网络抖动、演示导致心节点跳包心跳包接收异常 |
- |
- |
Raft 这套选举算法可以保证任意任期内最多只有一个主节点。
一个任期的的选举可能因为平局的缘故未选出主节点而开始一场新的选举,
那么这个任期内就没有主节点了。
另外 Raft 如何保证一个任期内不会出现多个主节点呢?
前面我们对 Raft 选主算法的介绍中提及——
候选节点总是投票给自己,从节点在一个任期内总是把票投给它第一个收到 RequsstVote RPC 的候选节点,
这个限制暨意味着一个任期内每个节点最多只能投票给一个节点,那么自然最多只有一个节点能的到超过半数的投票而成为主节点。
2. 选主模块实现上的考量
Raft 选主模块的实现中涉及到的多个操作的并发执行,
这其中关键去数据的并发读写保护是非常重要的一点。
选主算法中会并发执行的操作有:
- AppendEntries RPC 处理
- RequestVote RPC 处理
- Follower、Candidate、Leader 流程的执行(任意时刻一个节点只能执行一种角色的相关的流程)
这其中 Candidate、Leader 又需要执行并发的动作。
Candidate 需要并发向其他节点发送 RequestVote RPC,
Leader 需要并发向其他节点发送 AppendEntries RPC。
需要并发保护的关键区数据:
- 节点的角色
- 当前任期
- 节点的投票记录(voteFor)
在实现过程中必须十分小心这些并发操作对关键去数据的操作。
除此之外还有几个非常重要的点是:
- Raft 运行过程中一个 Follower 节点一旦收到一条当前任期的 AppendEntries 便需要重置当前的选举超时定时器,
有一种 AppendEntries RPC 的实现方式是异步的完成所有 AppendEntries 的操作然后再通知 Follower 重置定时器,
这种方式的问题在于AppendEntries 可能还未执行完毕 Follower 的选举超时定时器可能就超时了,
Raft 算法的实现应当避免这种问题;
- Follower 在 VoteFor RPC 请求并且给获选节点投票后,
也需要重置选举超时定时器,
否则可能出现 Follower 变成 Candidate 又开始一轮新的选举;
另外如果接受到 VoteFor RPC 但不需要重置定时器,
需要让原来设置的定时器继续运行,否则貌似会导致长时间无法选举出主节点;
- Candidate 在选举失败后,不能立即开始下一轮选举,
需要继续等待选举超时定时器,
因为在这期间可能会受到本轮选举中产生的主节点的心跳包,
过早的重置定时器开始下一轮选举会导致刚选出来的主机节点马上有变成从节点,
实际测试中发现 Candidate、Follower 类似错误的定时器实现会让算法的 CPU 飙升到 200% - 300%,
修复后同样的测试 CPU 则平稳在 5% 一下,这个差异有点吓人
- 尽量提高各个处理的并行度,可以避免定时器超时带来的多余选举