NUMA 简介
本文对 NUMA 做简要介绍,内容主要根据HPC-numa.pdf这一讲义整理。
NUMA 的全称是 None-Uniform Memory Access,即非一致性内存访问。
它是一种访存模型,这里访存的主体是 CPU,
非一致性指的是在多核的场景下不同的 CPU 访问内存的链路、延迟可能不一样。
与 NUMA 相对的是早期的 UMA 访存模型。
UMA 的访存模型比较简单,所有的 CPU 通过 FSB(Front Side Bus)连接北桥(Nothbridge)上的内存控制器来访问内存。
这种场景下所有 CPU 看到的内存是都是一致的,它们的访存延迟都是一样的。
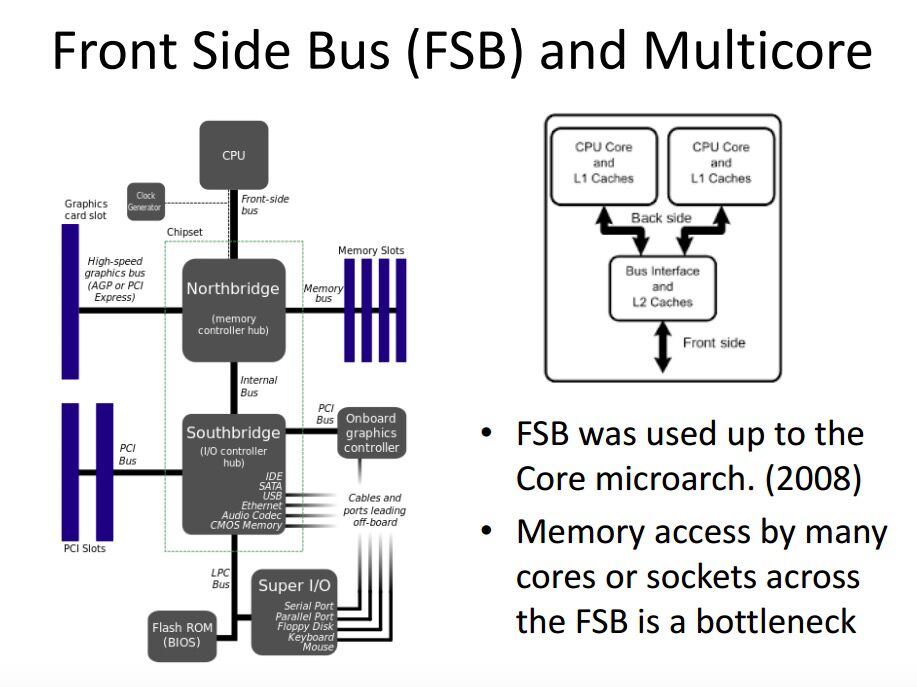
UMA 的问题在于,随着服务器上的核心数越来越多,FSB 很快就成了瓶颈,于是就出现了 NUMA。
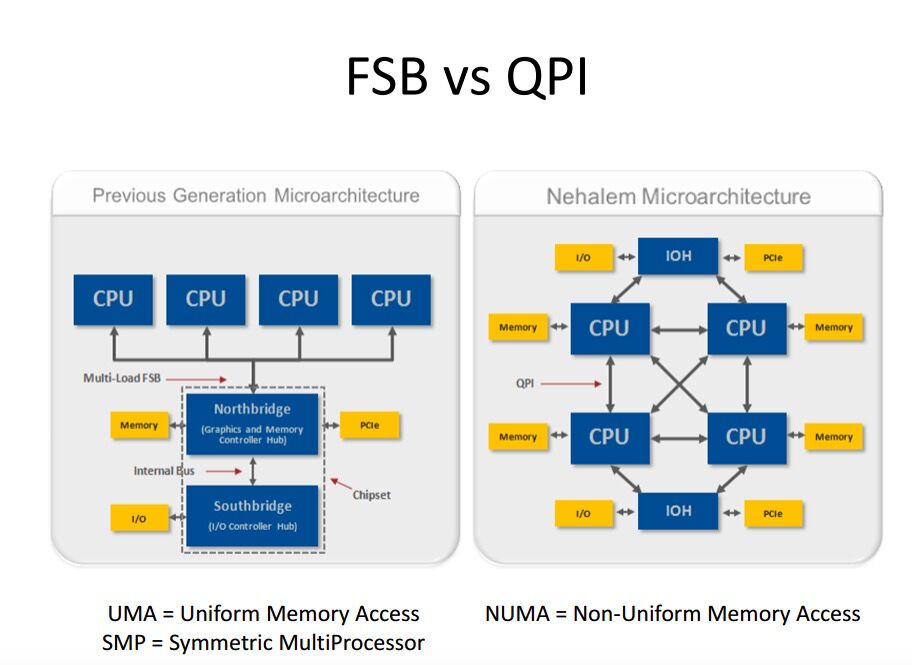
NUMA 场景中 CPU 和内存分隔组成不同的 NUMA node。
通常一颗物理 CPU 对应一个 NUMA node,也可能存在对应多个 NUMA node 的情况。
UMA 中内存控制器是做在主板上的北桥中,NUMA 中的内存控制器则在 CPU 中,CPU 可以直接访问内存。
一个 NUMA node 由一组 CPU 和它所直接控制的内存组成,CPU 通过 QPI 协议实现跨 node 间的内存访问。
NUMA 节点内的访存速度通常比跨节点间的内存访问快得多(快多少?两倍?)。
NUMA 的一些疑问
-
numa 场景下页表的分配采用first touch原则——即分配当前线程运行的 CPU 所属的 numa 节点中的内存,
那么问题来了,如果我们开启了 numa strict 策略,那这个线程是否就不会被调度到其他 numa 节点上的 CPU 来执行了?
-
numa 节点分配的 CPU 和内存插槽的物理位置是否相关,或者说主板上的内存插槽和 CPU socket 是否已经通过物理线路确定绑定关系了?