单例模式和内存屏障
单例模式是一个比较简单的设计模式,
但多线程场景下使用延迟加载的单例模式是一个经典的并发问题,
可能会需要使用锁和内存屏障来保障线程安全。
这篇文章主要讲并发场景下使用加载的单例模式的实现。
1. 非线程安全的单例实现
我们先考虑非线程安全的单例模式的实现
#include <stdio.h>
#include <stdlib.h>
struct singleton_t {
int val;
};
struct singleton_t *INSTANCE = NULL;
struct singleton_t *getInstance() {
if (INSTANCE == NULL) {
INSTANCE = malloc(sizeof(*INSTANCE));
INSTANCE->val = 8848;
}
return INSTANCE;
}
int main() {
struct singleton_t *inst = getInstance();
printf("hello: %p\n", inst);
return 0;
}
以上代码的问题在于,
当多个线程同时调用getInstance()函数时,
INSTANCE可呢个会被初始化多次,对此我们考虑使用锁来保障线程安全。
2. 线程安全的单例实现
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
struct singleton_t {
int val;
};
struct singleton_t *INSTANCE = NULL;
pthread_mutex_t lock;
struct singleton_t *getInstance() {
pthread_mutex_lock(&lock); // ignore error handling
if (INSTANCE == NULL) {
INSTANCE = malloc(sizeof(*INSTANCE));
INSTANCE->val = 8848;
}
pthread_mutex_unlock(&lock);
return INSTANCE;
}
int main() {
struct singleton_t *inst = NULL;
if (pthread_mutex_init(&lock, NULL) != 0) {
perror("error init mutext:");
return 1;
}
inst = getInstance();
printf("hello: %p\n", inst);
return 0;
}
这个版本我们使用互斥变量来保护INSTANCE变量的并发访问,
但是它有个问题:每次调用getInstance()都需要加锁操作,
性能太差,我们考虑进一步的优化。
3. 线程安全的单例实现——性能优化版
考虑到INSTANCE变量只要初始化一次就行了,
可以考虑做两次判断,第一次判断如果INSTANCE != NULL,我们可以直接返回了,
否则我们就先加锁,再判断一次INSTANCE变量,如果仍然为空我们才执行初始化操作,
这就是经典的double check操作。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
struct singleton_t {
int val;
};
struct singleton_t *INSTANCE = NULL;
pthread_mutex_t lock;
struct singleton_t *getInstance() {
if (INSTANCE == NULL) {
pthread_mutex_lock(&lock); // ignore error handling
if (INSTANCE == NULL) {
INSTANCE = malloc(sizeof(*INSTANCE));
INSTANCE->val = 8848;
}
pthread_mutex_unlock(&lock);
}
return INSTANCE;
}
int main() {
struct singleton_t *inst = NULL;
if (pthread_mutex_init(&lock, NULL) != 0) {
perror("error init mutext:");
return 1;
}
inst = getInstance();
printf("hello: %p\n", inst);
return 0;
}
但是这个版本的代码还有个明显的问题,我们看这两行代码:
INSTANCE = malloc(sizeof(*INSTANCE));
INSTANCE->val = 8848;
malloc()执行完毕后,
INSTANCE变量已经非空,
这时候其他线程已经可以获取INSTANCE变量,
但是INSTANCE还没有完成下一句的初始化操作:INSTANCE->val = 8848;!
修复这个问题的一个思路是,
我们先完成malloc()分配对象的初始化后再把这个值赋给INSTANCE变量,
这可以通过一个临时变量来完成,修改后的代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
struct singleton_t {
int val;
};
struct singleton_t *INSTANCE = NULL;
pthread_mutex_t lock;
struct singleton_t *getInstance() {
if (INSTANCE == NULL) {
pthread_mutex_lock(&lock); // ignore error handling
if (INSTANCE == NULL) {
struct singleton_t *tmp = malloc(sizeof(*INSTANCE));
tmp->val = 8848;
INSTANCE = tmp;
}
pthread_mutex_unlock(&lock);
}
return INSTANCE;
}
int main() {
struct singleton_t *inst = NULL;
if (pthread_mutex_init(&lock, NULL) != 0) {
perror("error init mutext:");
return 1;
}
inst = getInstance();
printf("hello: %p\n", inst);
return 0;
}
所以万事大吉了吗现在?
事情显然没那么简单,以上代码还是会受到并发问题的困扰!
在多核并发的场景下,由于缓存可见性问题,某个线程可能看到的结果是:
INSTANCE = tmp;
tmp->val = 8848;
也就是先给INSTANCE赋值再执行初始化操作。
要解决这个问题就得搬出内存屏障这个东西。
我们需要在这两行代码之前插入一个写屏障:
static inline void rmb() {
asm volatile("sfence":::);
}
...
tmp->val = 8848;
rmb();
INSTANCE = tmp;
...
写屏障可以保证INSTANCE = tmp;语句执行前所有的写操作相关的缓存得到更新。
又:内存屏障都是成对出现的,我们加了写屏障,还有其他地方也需要加读屏障以保证读取到正确的缓存数据,
关于读屏障放置的位置,我认为有两个地方都可以:或者放在代码开始处,或者放在INSTANCE变量返回前,最终代码如下:
static inline void wmb() {
asm volatile("sfence":::);
}
static inline void rmb() {
asm volatile("lfence":::);
}
struct singleton_t *getInstance() {
rmb();
if (INSTANCE == NULL) {
pthread_mutex_lock(&lock); // ignore error handling
if (INSTANCE == NULL) {
struct singleton_t *tmp = malloc(sizeof(*INSTANCE));
tmp->val = 8848;
wmb();
INSTANCE = tmp;
}
pthread_mutex_unlock(&lock);
}
// or here
// rmb();
return INSTANCE;
}
4. 内存屏障原理概述
关于内存屏障的介绍可以参考
Is Parallel Programming Hard, And, If So, What Can You Do About It?
这本书的附录 C. Why Memory Barriers?,
里面对内存屏障做了详细的讨论。
这里我尝试概括一下其中的原理。
首先多核的处理器中每颗 CPU 都有自己独立的缓存,
这就需要解决多核间缓存一致性的问题,
目前主要是通过 MESI 这个缓存一致性协议来保障多核间的缓存一致性。
MESI 协议解决了 CPU 之间的缓存一致性问题,
但在首次写缓存的时候性能比较差,
这是因为在写入缓存前它必须先等待缓存Invalidate操作执行完毕
(its performance for the first write to a given cache line is quite poor. )。

为了解决这个问题,硬件设计者引入了store buffer和store forwarding策略。
这样依赖,CPU 不必再等待invalidate操作才写入缓存,它直接将数据写入到store buffer,
后续同时从store buffer和缓存中检索数据(store forwarding策略)。
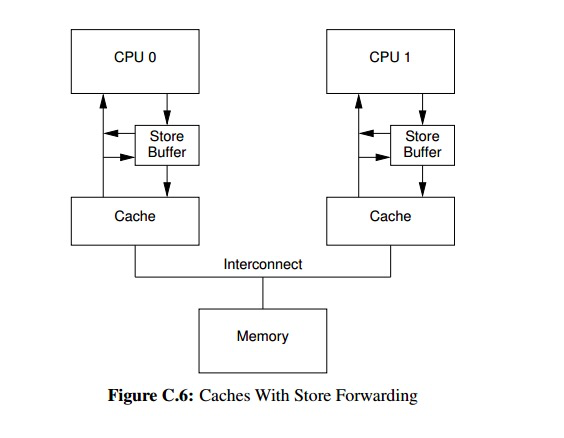
store buffer导致的一个问题是其他进程可能会读取到错误的旧数据。
例如假设有变量a = 0, b = 0,线程 A 执行一下代码:
a变量不在线程的缓存中,线程 A 首先执行invalidate操作,不等它执行完毕它就直接写入store buffer,
线程 A 继续执行b = 2,变量b在线程 A 的缓存中,其他线程可能在看到b = 2后仍然读取到a = 0。
为了解决这个问题,硬件设计者就引入了内存写屏障指令,
它的本质是强迫 CPU 在执行下一条store指令前先等待清空store buffer。
invalidate操作还会带来另外一种延迟,就是invalidate消息的确认。
当缓存组件换忙的时候,缓存的invalidate操作可能会花很长时间。
于是硬件设计者又引入了invalidate queue这一组件:
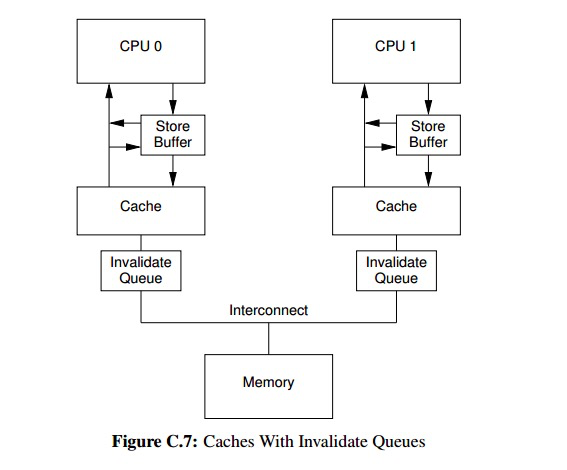
CPU 先把invalidate消息放到invalidate queue中,然后直接返回了,
等缓存invalidate操作执行完毕后在将相应的invalidate消息从invalidate queue中移除。
invalidate queue和store buffer一样也会导致缓存的可见性问题——即 CPU 读到本来应该已经被invalidate的缓存村数据。
为了解决这个问题硬件者又引入了内存读屏障指令,
它的作用是强迫 CPU 在执行下一条缓存 load 操作前先等待invalidate queue为空。
因为缓存的invalidate操作和invalidate acknowledge是一来一回相对应的,
所以我们看到的内存屏障总是成对的出现。
5. 后记
TODO: 示例中的代码没有测试过,可能是错的。
第一次了解内存屏障是在接触 Java 学习它的单例设计模式实现的的时候,
当时看到为了处理延迟加载导致的并发问题而使用了内存屏障,完全一头雾水,后来也没去深究。
前两年在处理一起应用死锁的故障时又碰到内存屏障,
特地去研究了下,当时感觉差不多看懂了,
一直到最近在和人交流单例中并发问题时,发现并没有完全搞懂内存屏障,
所以重新翻了Why Memory Barrier这篇文章,把单例的实现和内存屏障相关的知识点也整理在这篇笔记中。