kube-router 服务就绪慢问题分析
1. 问题简介
线下的 kube-router 运行一段时间后我们发现它存在一个令人难以忍受的问题:
每次遇到节点 crash 重启后,pod 的网络都需要很长时间才能就绪。
最近对这个问题做了研究,这篇文章对记录当时排查问题的经过,并提出问题的集中处理方法。
2. 问题分析
因为 kube-router 是基于 BGP 构建的 k8s 网络解决方案,
所以我们在节点上对针对 kube-router 的 BGP 通信做了抓包分析。
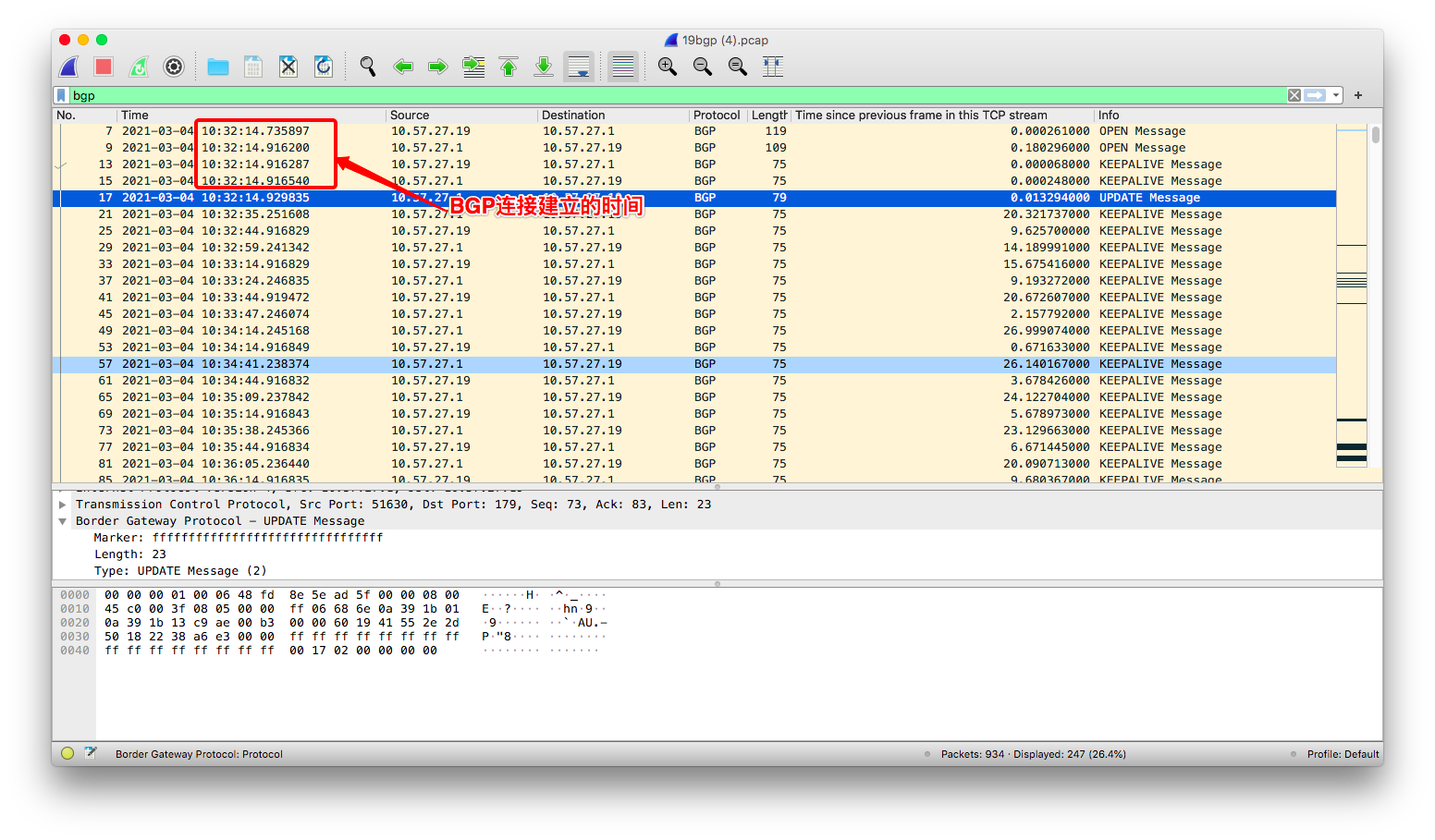
在抓包分析中我们发现在宕机超过 90s 后(我们把 BGP graceful restart period 设为 90s),
从 kube-rouer 和交换机建立 peer 关系到它上报第一条路由 update 消息隔了六分钟,
而且这一现象可以稳定复现。
(1) peer 关系建立时间
(2) kube-router 第一条路由上报时间
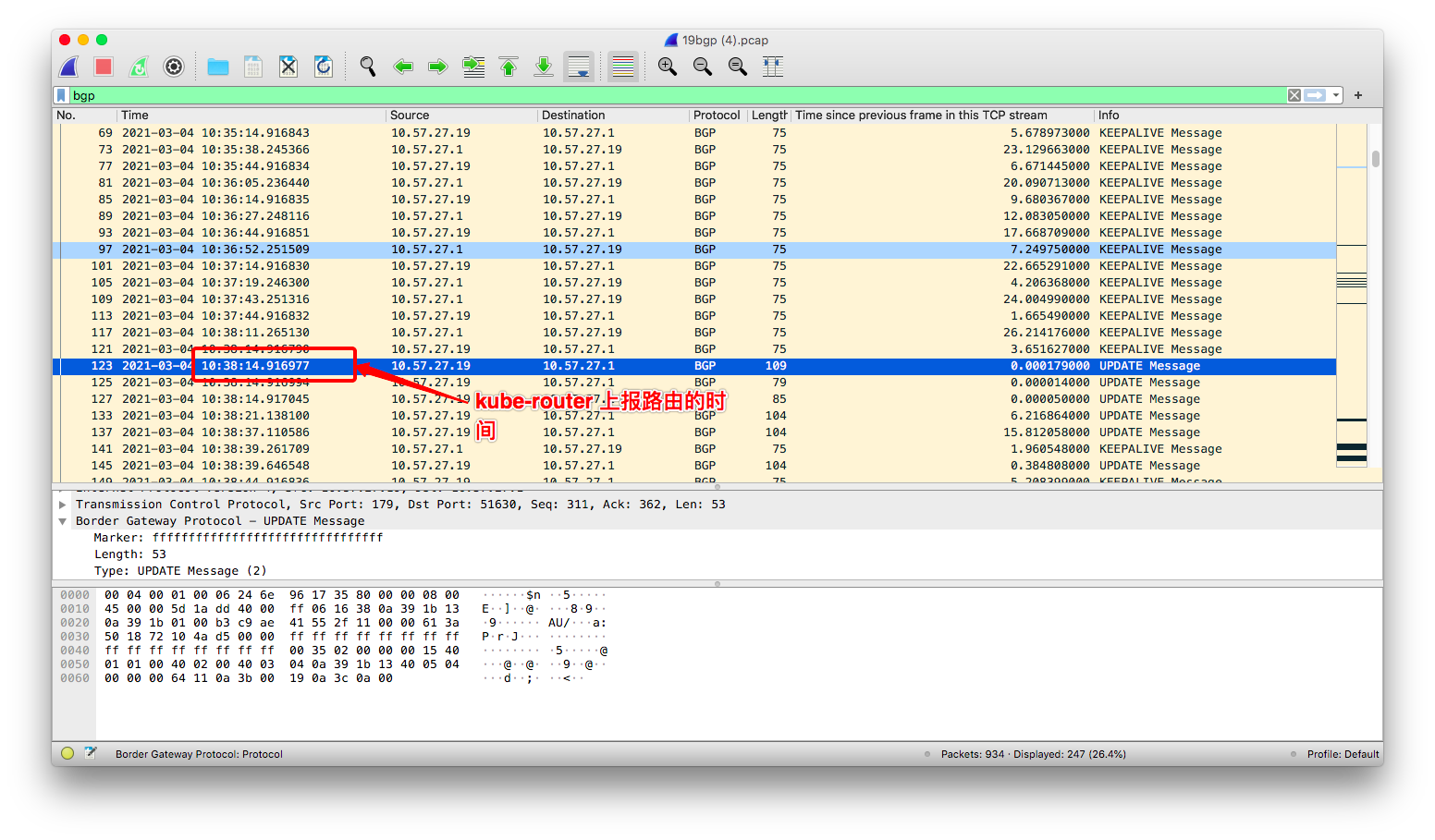
通过跟踪 kube-router 代码,
我们发现当前场景下 kube-router 的第一条路由 update 消息的发送是通过一个定时器触发的(vendor/github.com/osrg/gobgp/pkg/server/server.go):
1486 // RFC 4724 4.1
1487 // Once the session between the Restarting Speaker and the Receiving
1488 // Speaker is re-established, ...snip... it MUST defer route
1489 // selection for an address family until it either (a) receives the
1490 // End-of-RIB marker from all its peers (excluding the ones with the
1491 // "Restart State" bit set in the received capability and excluding the
1492 // ones that do not advertise the graceful restart capability) or (b)
1493 // the Selection_Deferral_Timer referred to below has expired.
1494 allEnd := func() bool {
1495 for _, p := range s.neighborMap {
1496 if !p.recvedAllEOR() {
1497 return false
1498 }
1499 }
1500 return true
1501 }()
1502 if allEnd {
1503 for _, p := range s.neighborMap {
1504 p.fsm.lock.Lock()
1505 p.fsm.pConf.GracefulRestart.State.LocalRestarting = false
1506 p.fsm.lock.Unlock()
1507 if !p.isGracefulRestartEnabled() {
1508 continue
1509 }
1510 paths, _ := s.getBestFromLocal(p, p.configuredRFlist())
1511 if len(paths) > 0 {
1512 sendfsmOutgoingMsg(p, paths, nil, false)
1513 }
1514 }
1515 log.WithFields(log.Fields{
1516 "Topic": "Server",
1517 }).Info("sync finished")
1518 } else {
1519 peer.fsm.lock.RLock()
1520 deferral := peer.fsm.pConf.GracefulRestart.Config.DeferralTime
1521 peer.fsm.lock.RUnlock()
1522 log.WithFields(log.Fields{
1523 "Topic": "Peer",
1524 "Key": peer.ID(),
1525 }).Debugf("Now syncing, suppress sending updates. start deferral timer(%d)", deferral)
1526 time.AfterFunc(time.Second*time.Duration(deferral), deferralExpiredFunc(bgp.RouteFamily(0)))
1527 }
注意这行代码time.AfterFunc(time.Second*time.Duration(deferral),
其中deferralExpiredFunc(bgp.RouteFamily(0)))会发送第一条 BGP 路由 update 消息,
触发时间由deferral变量控制。
而deferral变量的赋值则是deferral := peer.fsm.pConf.GracefulRestart.Config.DeferralTime,
通过简单的检索,
可以发现peer.fsm.pConf.GracefulRestart.Config.DeferralTime参数是由 kube-router 的命令行参数控制:
--bgp-graceful-restart-deferral-time duration BGP Graceful restart deferral time according to RFC4724 4.1, maximum 18h. (default 6m0s)
这个参数默认配置是六分钟,
而我们抓包分析观察到的服务就绪延迟也刚好是六分钟。
通过测试,
我们发现 kube-router 第一条路由 update 消息的发送时间完全可由这个参数控制。
所以解决 kube-router 服务就绪时间长的一种可行的解决方案就是通过调整这个参数来缩短延迟。
但是,我们需要搞清楚这个参数到底有什么作用。
从 –bgp-graceful-restart-deferral-time 参数的注释上我们注意到这个参数和 RFC 4724 有关,
而这份 RFC 是专门讲 BGP 优雅重启的。
我们在 RFC 4724 4.1 这一节中看到一段非常有意思的话:
Once the session between the Restarting Speaker and the Receiving
Speaker is re-established, the Restarting Speaker will receive and
process BGP messages from its peers. However, it MUST defer route
selection for an address family until it either (a) receives the
End-of-RIB marker from all its peers (excluding the ones with the
“Restart State” bit set in the received capability and excluding the
ones that do not advertise the graceful restart capability) or (b)
the Selection_Deferral_Timer referred to below has expired. It is
noted that prior to route selection, the speaker has no routes to
advertise to its peers and no routes to update the forwarding state.
它解释了 GBP 优雅重启后发送第一调路由 update 消息的两种情况:
- a: 收到 peer 端发送过来的 End-of-RIB 消息
- b: 否则就等待 Selection_Deferral_Timer 定时器超时
我们在上面摘录的 kube-router 代码中可以看到它在注释里把这段话完整的抄下来了。
所以我们遇到的问题应该是 kube-router 没收到 peer 端发送的 EOR(End-of-RIB)消息它才执行 b 这一分支——至少 kube-router 认为它自己是没收到 EOR 消息的。
根据 RFC 4724 中的定义,
EOR 本质上就是一条空的 BGP update 消息,
从我们抓包的截图上我们可以看到交换机在和 kube-router 建立 peer 关系后马上就给 kube-router 发送了一条空的 update 消息。
为什么 kube-router 还是掉进 b 这个分支呢?
仍然在以上代码的基础上分析,
可知对 a 情况的判断实际上是用了以下函数:
1494 allEnd := func() bool {
1495 for _, p := range s.neighborMap {
1496 if !p.recvedAllEOR() {
1497 return false
1498 }
1499 }
1500 return true
1501 }()
核心的点是 p.recvedAllEOR() 这个函数,vendor/github.com/osrg/gobgp/pkg/server/peer.go:
191 func (peer *peer) recvedAllEOR() bool {
192 peer.fsm.lock.RLock()
193 defer peer.fsm.lock.RUnlock()
194 for _, a := range peer.fsm.pConf.AfiSafis {
195 if s := a.MpGracefulRestart.State; s.Enabled && !s.EndOfRibReceived {
196 return false
197 }
198 }
199 return true
200 }
peer.fsm.pConf.AfiSafis 是 BGP 地址族信息相关的配置,
我们在 vendor/github.com/osrg/gobgp/pkg/server/fsm.go 可以看到相应的设置代码:
1331 if fsm.pConf.GracefulRestart.Config.Enabled && ok {
1332 state := &fsm.pConf.GracefulRestart.State
1333 state.Enabled = true
1334 cap := gr[len(gr)-1].(*bgp.CapGracefulRestart)
1335 state.PeerRestartTime = uint16(cap.Time)
1336
1337 for _, t := range cap.Tuples {
1338 n := bgp.AddressFamilyNameMap[bgp.AfiSafiToRouteFamily(t.AFI, t.SAFI)]
1339 for i, a := range fsm.pConf.AfiSafis {
1340 if string(a.Config.AfiSafiName) == n {
1341 fsm.pConf.AfiSafis[i].MpGracefulRestart.State.Enabled = true
1342 fsm.pConf.AfiSafis[i].MpGracefulRestart.State.Received = true
1343 break
1344 }
1345 }
1346 }
fsm.pConf.AfiSafis[i].MpGracefulRestart.State.Enabled = true是在协商阶段执行的设置,
我们在代码里只看到将 peer 这个配置设置为 true 的操作。
peer 端的 AfiSafi 由 kube-router 配置,
kube-router 默认给配置了 ipv4 和 ipv6 两个地址族,
而且两个地址族默认 Enabled 配置都是 true,
pkg/controllers/routing/bgp_peers.go:
112 n.AfiSafis = []*gobgpapi.AfiSafi{
113 {
114 Config: &gobgpapi.AfiSafiConfig{
115 Family: &gobgpapi.Family{Afi: gobgpapi.Family_AFI_IP, Safi: gobgpapi.Family_SAFI_UNICAST},
116 Enabled: true,
117 },
118 MpGracefulRestart: &gobgpapi.MpGracefulRestart{
119 Config: &gobgpapi.MpGracefulRestartConfig{
120 Enabled: true,
121 },
122 State: &gobgpapi.MpGracefulRestartState{},
123 },
124 },
125 {
126 Config: &gobgpapi.AfiSafiConfig{
127 Family: &gobgpapi.Family{Afi: gobgpapi.Family_AFI_IP6, Safi: gobgpapi.Family_SAFI_UNICAST},
128 Enabled: true,
129 },
130 MpGracefulRestart: &gobgpapi.MpGracefulRestart{
131 Config: &gobgpapi.MpGracefulRestartConfig{
132 Enabled: true,
133 },
134 State: &gobgpapi.MpGracefulRestartState{},
135 },
136 },
137 }
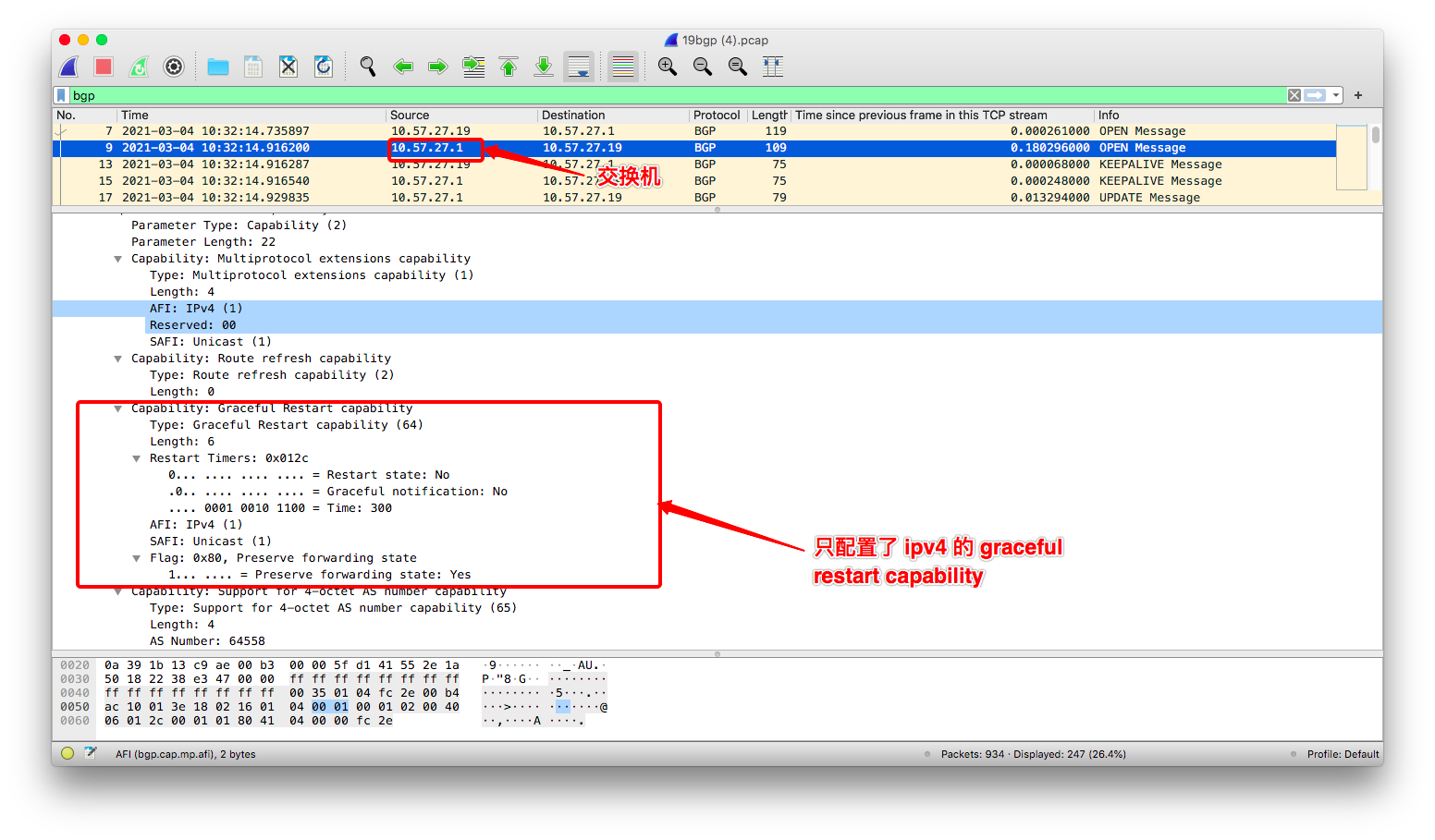
再回头分析我们之前抓下来的 BGP 通信包:
(3) 交换机上的 BGP cap 设置:
(3) kube-router 上的 BGP cap 设置:
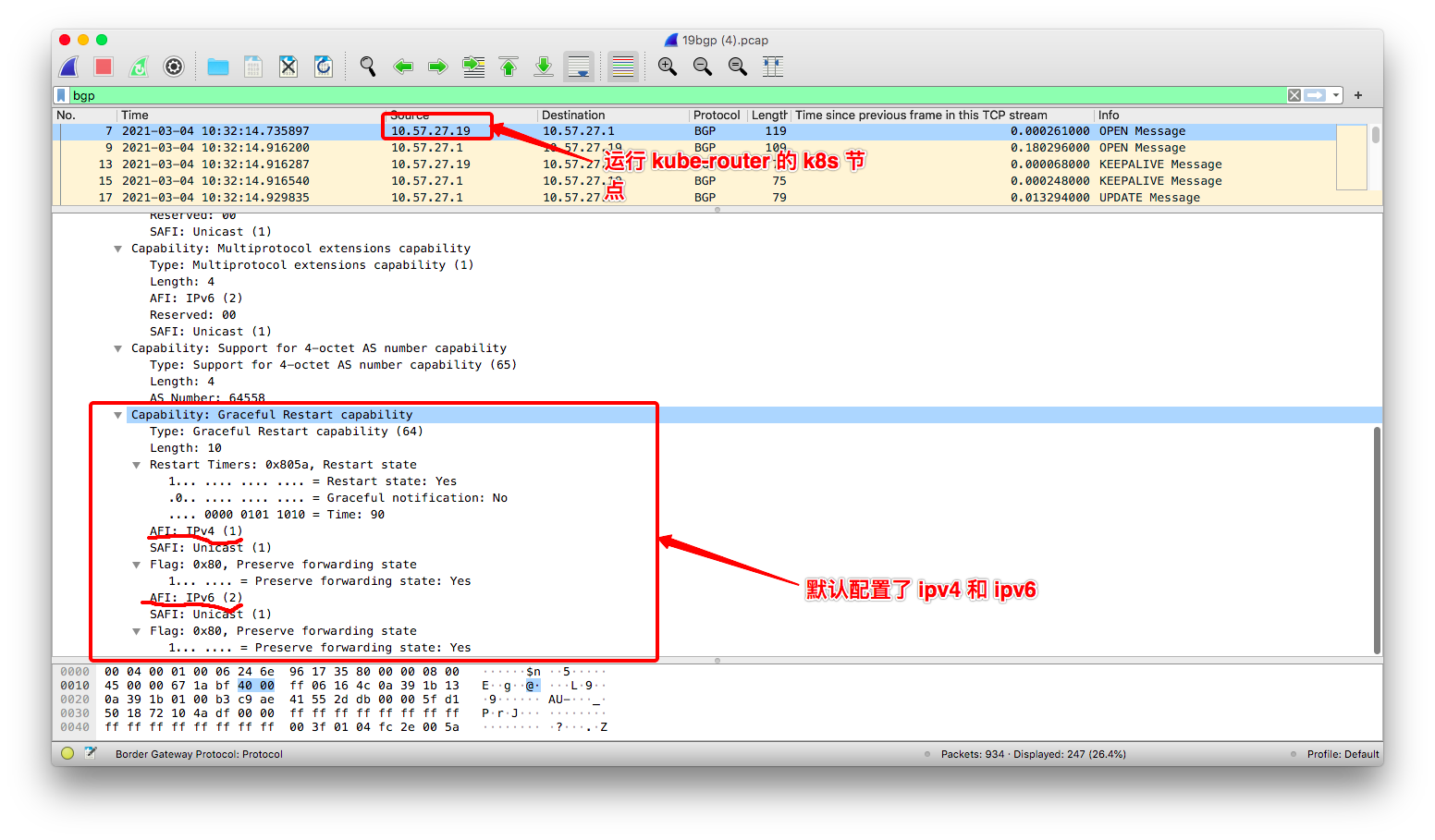
由此,即便交换机已经发送了 EOR 消息,
kube-router 仍然认为它没有收到交换机 ipv6 地址族的 EOR,
所以,kube-router 代码在执行的时候就退化到 RFC 4724 4.1 节中描述的 b 情况,
也就是等待六分钟的 Selection_Deferral_Timer 定时器超时。
3. 解决方案
通过以上分析,针对 kube-route 就绪时间过长问题我们可以有以下几种解决办法:
- 调整 kube-router 的 bgp-graceful-restart-deferral-time 参数
- 或者通过修改 kube-router 代码调整 ipv6 相关配置(相关代码我们已经提交给社区)
- 开启交换机上的 ipv6 支持