k8s 网络抖动问题排查(二)
我们的 k8s 集群很早就出现过网络抖动的问题,见一次 k8s 网络抖动问题排查,
当时的问题是由于 BGP 路由环路导致的,而差不多同一时期我们发现 k8s 集群还存在另外一个网络抖动问题,
即服务 RT p999 的抖动问题。
我们从监控上发现部分服务从虚拟机迁移到容器后 RT p999,几乎翻倍。
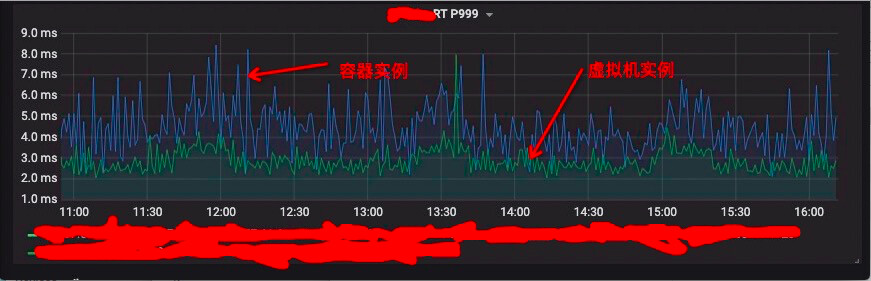
当时我们一度怀疑和进程调度、CPU 亲和性等问题有关。
但是使用runqlat 发现调度队列并没有明显的延迟,
我们给 k8s 节点开启了CPU Manager static policy,
当时发现的情况下部分机器的 RT p999 优化到虚拟机的水平,但是剩下的机器还是有很严重的抖动。
我们又怀疑过是网络抖动问题,
从 hping3 测试中似乎发现 k8s 节点的抖动高于虚拟机,
但是重复的抓包显示链路上的数据包往返明没有明显的 rt 延迟,
我艹艹艹,真是感觉黔驴技穷了。
当时没有进一步排查的思路,这个问题就这么一直存在着。
直到最近,在研究 trace 的时候发现一篇文章Kernel trace tools(一):中断和软中断关闭时间过长问题追踪,
它介绍了一个用于排查 hardirq/softirq 阻塞的内核模块工具。
这个工具原理本身很简单,代码也好理解,实际上bpf 已经有类似的 trace 工具。
但看这篇文章的时候我就在想,网络数据包经过中断到 DMA 后是不是通过 softirq 向上层协议栈继续交付数据的?
带着这个问题,我在Professional Linux Kernel Architecture翻到这么一张图:
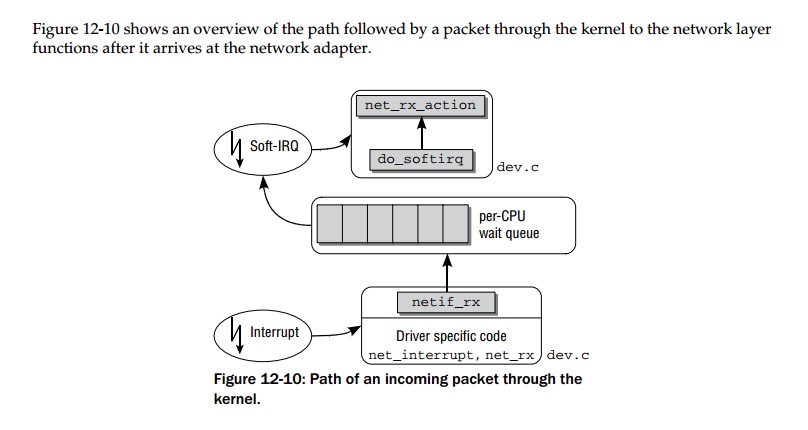
可以看到 Linux 正是通过 softirq 继续向协议栈交付数据包的。
此时我感觉 softirq 入手去查这个问题是个非常有价值的方向。
在 k8s 测试节点上把这个工具跑起来,
然后欣喜的发现数不清的 softirq 延迟堆栈现场,而其中大部分跟 ipvs 模块的一个 estimation_timer 定时器有关:
COMMAND: swapper/21 PID: 0 LATENCY: 148ms
save_stack_trace+0x1b/0x20
trace_irqoff_record+0x25e/0x290 [trace_irqoff]
trace_irqoff_timer_handler+0x47/0x7c [trace_irqoff]
call_timer_fn+0x35/0x140
run_timer_softirq+0x1e8/0x450
__do_softirq+0xc9/0x269
irq_exit+0xd9/0xf0
smp_apic_timer_interrupt+0x69/0x130
apic_timer_interrupt+0xa9/0xb0
cpu_idle_poll+0x39/0x150
do_idle+0x44/0x1e0
cpu_startup_entry+0x73/0x80
start_secondary+0x195/0x1f0
secondary_startup_64+0xa5/0xb0
COMMAND: swapper/21 PID: 0 LATENCY: 56+ms
estimation_timer+0x6e/0x1f0 [ip_vs]
call_timer_fn+0x35/0x140
run_timer_softirq+0x1e8/0x450
__do_softirq+0xc9/0x269
irq_exit+0xd9/0xf0
smp_apic_timer_interrupt+0x69/0x130
apic_timer_interrupt+0xa9/0xb0
cpu_idle_poll+0x39/0x150
do_idle+0x44/0x1e0
cpu_startup_entry+0x73/0x80
start_secondary+0x195/0x1f0
secondary_startup_64+0xa5/0xb0
通过阅读 ipvs 我们发现这个定时器的主要功能是统计 ipvs 实例做链接、流量等信息统计。
再看单个 k8s 节点上的 ipvs 负载均衡实例,有将近上万个实例。
几乎就能断言这就是容器抖动的来源了。
那这个问题怎么修复,一个比较暴力的做法就是直接把 ipvs 模块中的这个统计定时器关掉。
我把这部分代码注释调然后重新加载 ipvs,
在后续的 hping3 测试中我们发现未修复过的节点和修复过的节点表现出明显的差异,
在大于 10ms 的 hping3 超时记录中,前者是后者的三倍多,基本上可以实锤了。
然后再来回答几个先前无法解释的问题。
为什么绑核后有的节点上的实例 RT 不抖动了?
这可能和 ipvs 这个统计 timer 的 CPU 绑定有关,
具体出处我倒是忘了,但是有看到描述说这个 timer 会一直运行在最初加载 ipvs 模块的 CPU 上,
所以我们绑核后看到部分实例 RT 得到优化可能是他绑定的 CPU 和 timer 运行的 CPU 错开了。
另外一个问题是 wireshark 里面为什么没有看到数据包往返的延迟?
这一点应该和 bpf 的运行机制有关。
从bpf 的论文上
我们可以看出 bpf 直接在数据链路上抓的包:
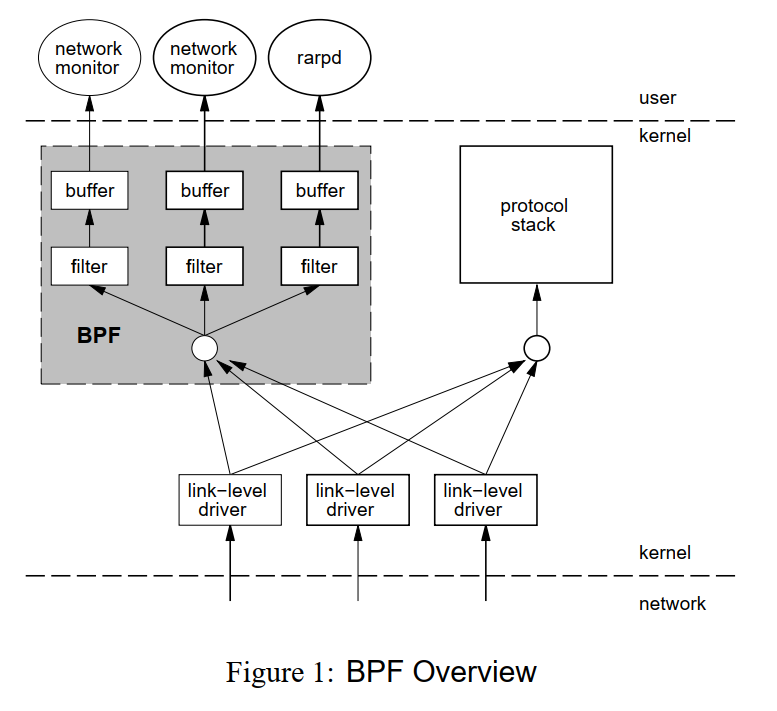
其实从这个我也无法做出确定的判断,
但是我猜测 bpf 在数据到达 softirq 前就被 bpf 获取到了,
或者我之前的抓包分析是错的……